今年6月份B站暗搓搓(反正我觉得是)上线了个"智能防挡弹幕". 已经记不得自己是什么时候发现的了, 只是觉得有点好玩, 但也仅此而已. 现在闲着无聊, 猜测一下其原理并验证一下. 如果更无聊的话, 再做个demo.
What is 智能防挡弹幕
其实就是视频中的人形区域允许弹幕从其"底下"穿过, 做到防止关键♂部位被文字盖住的劳什子功能. 效果见Banner, 虽然雷总没啥可挡的. 多见于尬舞区视频, 我并没有看到很多, 真的.
Brain Storm
乍一看这个功能大体分为两部分:
- 识别出视频中的目标(人形)区域
- 用区域信息对弹幕文字进行类似mask的处理
其实挺显而易见的, 并且两部分技术上相互独立, 可以分别解决. 前一个问题, 可以简化为Image Segmentation问题, 后一个就是遮罩样式了.
Image Segmentation
这个问题本应该是我的知识盲区, 但前两天刚刚在Udemy上看完了ROS和OpenCV的教程, 所以算是刚好入了门. 从应用的角度来讲也没有什么火箭科学: 对视频的逐帧扫描, 用图像识别算法划分区域.
例如:


从左图到右图的segmentation, 在OpenCV中只需要几行代码即可.
import numpy as np
import cv2 as cv
from matplotlib import pyplot as plt
img = cv.imread('coins.png')
gray = cv.cvtColor(img,cv.COLOR_BGR2GRAY)
ret, thresh = cv.threshold(gray,0,255,cv.THRESH_BINARY_INV+cv.THRESH_OTSU)上个例子只是最简单的Threshold分割, 对于人形的识别想必是需要更复杂的算法支持, 但原理上就是如此了. 经过一番google, 发现Mask_RCNN正是用来做此事的, 不知道是否实际用的这个.
到这里, 图像识别及蒙版生成的原理大概清楚了. 还有一个问题是, 对视频的生成蒙版的过程是实时的还是预处理的? 根据计算量估计应该是需要利用GPU预处理的, 但也不排除有什么前端黑科技, 毕竟Web开发什么都有可能发生. 后面验证部分再看.
遮罩样式
这个本来应该是老本行了, 但是乍一想竟然想不到用什么具体方法, 只是知道css应该可行. 实际上确实如此, css中有一个mask-*系列属性正是用来实现遮罩效果, 据说比border-radius还要古老, 但似乎兼容性并不是特别理想, 只在webkit上有效.
具体使用方法跟background类似, 可以支持普通图片和svg, 如果是图片则根据该图片的alpha通道进行遮盖. 也就是说假如用了jpg之类没alpha通道的格式, 就是全被盖住的效果了:
.mask-target {
mask-image: url(mask.png);
}这个方法仅限于基于html的弹幕系统, 移动端或flash播放器要另辟蹊径了.
验证
关于遮罩信息的生成, 无法确定B站到底采用的什么方案, 但至少可以验证是否实时的问题. 实际结果与预期相符, 每个支持智能防挡弹幕的视频都会去请求一个.webmask文件, 没有这个功能的视频就没有. 这个二进制文件不大不小, 3分钟的视频有2m多, 也符合性质. 证实了这一过程是经过预处理的.
样式的处理, 验证起来就简单了. 打开开发工具锁定到弹幕的元素:

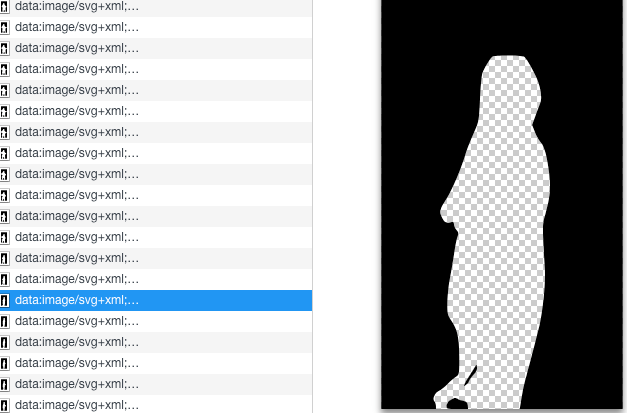
可以发现B站正是用mask-*来实现的此功能, 顺手拿Edge打开了一下相同视频, 果然也没有相关的开关了. Svg的信息应该来自于.webmask文件, 并根据时间轴加载到弹幕元素上. 这样的操作竟然没有带来很明显的负担, 如今前端的想象空间确实很大.
整体来讲, 结论符合B站在发布这个功能时的要求: 1, 仅特定视频 2, 仅限web端chrome内核. 该功能依赖于图像识别算法, 想象空间很大, 但目前实际效果可能仅在尬舞区有所体现.
完. 有空再做个demo. 溜了.